设为首页
收藏本站
请登录
立即注册
论坛首页
BBS
充值赞助
申请提现
提现排行榜
排行榜
Ranklist
友链申请
搜索
本版
文章
帖子
群组
用户
请
登录
后使用快捷导航
没有账号?
立即注册
友情链接
当前位置:
»
论坛首页
›
YOLO图像识别
›
前言资讯
›
不会写诗 只会做事!华为云正式发布盘古大模型3.0 ...
收藏
0
回复
不会写诗 只会做事!华为云正式发布盘古大模型3.0
IP属地:
香港
161
0
脆脆鲨
2023-9-27 13:35:39
|
显示全部楼层
|
阅读模式
【CNMO新闻】7月7日,在华为开发者大会(Cloud)期间,华为云盘古大模型3.0正式发布。华为云CEO张平安介绍,盘古大模型3.0是完全面向行业的大模型,包含L0基础大模型、L1行业大模型及L2场景模型三层架构,重点面向政务、金融、制造、医药、矿山、铁路、气象等行业。
据悉,在今天举行的华为开发者大会上,华为常务董事、华为云CEO张平安发表了主题演讲《一切皆服务,AI重塑千行百业》。在演讲中,张平安提到,盘古大模型不会写诗,只会做事,因此盘古大模型将专注于价值场景,致力于在政务、金融、制造、煤矿、铁路、制药、气象等行业深耕。
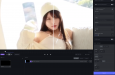
华为云CEO-张平安
据CNMO了解,盘古大模型 3.0 是一个完全面向行业的大模型系列,包括 5+N+X 三层架构,第一层L0层是盘古的5个基础大模型,包括自然语言大模型、视觉大模型、多模态大模型、预测大模型、科学计算大模型,它们提供满足行业场景的多种技能。
第二层 L1 层是 N 个行业大模型,我们既可以提供使用行业公开数据训练的行业通用大模型,包括政务,金融,制造,矿山,气象等;也可以基于行业客户的自有数据,在盘古的L0和L1上,为客户训练自己的专有大模型。
第三层 L2 层是为客户提供更多细化场景的模型,它更加专注于某个具体的应用场景或特定业务,为客户提供开箱即用的模型服务。
版权所有,未经许可不得转载
回复
使用道具
举报
提升卡
置顶卡
沉默卡
喧嚣卡
变色卡
千斤顶
照妖镜
返回列表
发新帖
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
脆脆鲨
管理员
关注
4885
主题
0
粉丝
0
关注
这家伙很懒,什么都没留下!
OCR文字识别工具和文件整合包
2024-8-28
Topaz Video AI v3.4.4 人工智能视频画质增强和修复软件
2024-8-28
VITS_fast_finetune 语音模型一键训练整合包
2024-8-28
Stable Diffusion整合包v4.9发布!解压即用 防爆显存 三分钟入门AI绘画 ☆更新 ☆训练
2024-8-28
Yolo_v8轻量版全套工具及易模块和例子支持CPU CUDA10 11
2024-8-28
发新帖
24小时热帖
Topaz Video AI v3.4.4 人工智能视频画质增
2024-08-28
VITS_fast_finetune 语音模型一键训练整合
2024-08-28
Stable Diffusion整合包v4.9发布!解压即用
2024-08-28
Yolo_v8轻量版全套工具及易模块和例子支持C
2024-08-28
AI再显神通!将大脑信号转为语音 准确率最
2023-09-20
Copyright © 2001-2025
Discuz Team.
Powered by
Discuz!
X3.5
|
网站地图



 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜